Named Entity Recognition
Source: A Survey on Deep Learning for Named Entity Recognition
Abstract
Named entity recognition (NER) is the task to identify text spans that mention named entities, and to classify them into predefined categories such as person, location, organization etc. NER serves as the basis for a variety of natural language applications such as question answering, text summarization, and machine translation.
命名实体识别(NER)旨在从文本中识别出特殊对象,这些对象的语义类别通常在识别前被预定义好,预定义类别如人、地址、组织等。命名实体识别不仅仅是独立的信息抽取任务,它在许多大型自然语言处理应用系统如信息检索、自动文本概要、问答任务、机器翻译以及知识建库(知识图谱)中也扮演了关键的角色。
This paper introduced four aspects of the NER:
- Introduced NER resources, including tagged NER corpora and off-the-shelf NER tools.
- Systematically categorized existing works based on a taxonomy along three axes: distributed representations for input, context encoder, and tag decoder.
- The most representative methods for recent applied techniques of deep learning in new NER problem settings and applications.
- The challenges faced by NER systems and outline future directions in this area.
这篇文章主要介绍了NER的四个方面
- 介绍了NER的资源,包括标签化的NER词库和现成的NER工具
- 基于分类法从三个角度对现有的工作进行系统的分类:输入的分布式表示,内容编码器,标签解码器
- 深度学习的最新应用技术在新的NER问题设置和应用中的最具代表性的方法
- NER系统所面临的挑战以及在这一领域的未来发展方向。
Introduction
Named Entity
The author divides named entities into two categories:
- generic named entities,such as people and places.
- specific domain named entities,such as proteins,genes.
This paper focuses on the first type of named entity recognition task in English.
作者讲命名实体分为两类:
- 常见的命名实体,如人名和地名
- 特殊领域的命名实体,如蛋白质、基因
这篇文章主要聚焦于英文的第一类命名实体识别的任务。
Methods for NER
- Rule-based approaches, which do not need annotated data as they rely on hand-crafted rules
- Unsupervised learning approaches, which rely on un-supervised algorithms without hand-labeled training examples
- Feature-based supervised learning approaches, which rely on supervised learning algorithms with careful feature engineering
- Deep-learning based approaches, which automatically discover representations needed for the classification and/or detection from raw input in an end-to-end manner.
- 基于规则的方法
- 无监督方法
- 基于特征的监督学习方法
- 深度学习方法
上述分类法并非泾渭分明的,比如某些深度学习方法也结合了一些研究者设计的特征来提高识别的准确率。
Formalize Definition
Given a sequence of tokens s=<w1,w2,…,wn>s=<w1,w2,…,wn>, NER is to output a list of tuples <Is,Ie,t><Is,Ie,t>, each of which is a named entity mentioned in ss. Here, Is∈[1,N]Is∈[1,N] and Ie∈[1,N]Ie∈[1,N] are the start and the end indexes of a named entity mention; tt is the entity type from a predefined category set. Example as:

给定标识符集合 s=<w1,w2,…,wn>s=<w1,w2,…,wn> ,NER 输出一个三元组的 <Is,Ie,t><Is,Ie,t> 列表,列表中的每个三元组代表 ss 中的一个命名实体。此处 Is∈[1,N]Is∈[1,N],Ie∈[1,N]Ie∈[1,N] 分别为命名实体的起始索引以及结束索引;tt 指代从预定义类别中选择的实体类型
Tasks of NER
- Coarse-grained NER: focuses on a small set of coarse entity types and one type per named entity
- Fine-grained NER: focus on a much larger set of entity types where a mention may be assigned multiple types
NOTE: The change of NER task from coarse to fine is closely related to the development of annotated data sets from small to large
- 粗粒度的NER(实体种类少,每个命名实体对应一个实体类型)
- 细粒度的NER(实体种类多,每个命名实体可能存在多个对应的实体类型)
值得一提的是,NER任务从粗到细的变化与标注数据集从小到大的发展密切相关
NER Resources
- Datasets
High quality annotation are critical for both model learning and evaluation. Before 2005, datasets were mainly developed by annotating news articles with a small number of entity types, suitable for coarse-grained NER tasks. After that, more datasets were developed on various kinds of text sources including Wikipedia articles, conversation, and user-generated text(e.g., tweets and YouTube comments and StackExchange posts in W-NUT). The number of tag types becomes significantly larger, e.g., 89 in OntoNotes.
Note that many recent NER works report their perfor-mance on CoNLL03 and OntoNotes datasets, they are used for coarse-grained and fine-grained NER tasks, respectively.
有监督方法的NER任务依赖标注数据集。2005 年之前,数据集主要通过标注新闻文章得到并且预定义的实体种类少,这些数据集适合用于粗粒度的NER任务; 2005 年之后,数据集来源越来越多,包括但不限于维基百科文章、对话、用户生成语料(如推特等社区的用户留言)等,并且预定义的实体类别也多了许多,以数据集 OneNotes 为例,其预定义的实体类别达到了89种之多。
所有数据集中,最常见的数据集为 CoNLL03 和 OneNotes,分别常见于粗粒度的NER任务和细粒度的NER任务。
- Tools
Off-the-shelf NER tools offered by academia and industry/open source projects.
现成的NER工具来源于学界、工业界以及开源项目
| NER System | URL |
|---|---|
| StanfordCoreNLP | https://stanfordnlp.github.io/CoreNLP/ |
| OSU Twitter NLP | https://github.com/aritter/twitter_nlp |
| Illinois NLP | http://cogcomp.org/page/software/ |
| NeuroNER | http://neuroner.com/ |
| NERsuite | http://nersuite.nlplab.org/ |
| Polyglot | https://polyglot.readthedocs.io/ |
| Gimli | http://bioinformatics.ua.pt/gimli |
| spaCy | https://spacy.io/ |
| NLTK | https://www.nltk.org/ |
| OpenNLP | https://opennlp.apache.org/ |
| LingPipe | http://alias-i.com/lingpipe-3.9.3/ |
| AllenNLP | https://allennlp.org/models |
| IBM Watson | https://www.ibm.com/watson/ |
Evaluation Metrics
NER systems are usually evaluated by comparing their outputs against human annotations. The comparison can be quantified by
- Exact-match
- Relaxed match
通常通过与人类标注水平进行比较判断NER系统的优劣。评估分两种:
- 精确匹配评估
- 宽松匹配评估
Exact-match Evaluation
NER involves identifying both entity boundaries and entity types. With “exact-match evaluation”, a named entity is considered correctly recognized only if its both boundaries and type match ground truth. Precision, Recall, and F-score are computed on the number of true positives(TP), false positives(FP), and false negatives(FN).
- True Positive(TP): entities that are recognized by NER and match ground truth.
- False Positive(FP): entities that are recognized by NER but do not match ground truth.
- False Negative(FN): entities annotated in the ground truth that are not recognized by NER.
NER任务需要同时确定实体边界以及**实体类别。**在精确匹配评估中,只有当实体边界以及实体类别同时被精确标出时,实体识别任务才能被认定为成功。基于数据的 true positives(TP),false positives(FP),以及false negatives(FN),可以计算NER任务的精确率,召回率以及 F-score 用于评估任务优劣。对NER中的 true positives(TP),false positives(FP)与false negatives(FN)有如下解释:
- true positives(TP):NER能正确识别实体
- false positives(FP):NER能识别出实体但类别或边界判定出现错误
- false negatives(FN):应该但没有被NER所识别的实体
Precision measures the ability of a NER system to present only correct entities, and Recall measures the ability of a NER system to recognize all entities in a corpus.
$Precision=\frac{TP}{TP+FP}$
$Recall=\frac{TP}{TP+FN}$
F-score is the harmonic mean of precision and recall, and the balanced F-score is most commonly used:
$F{score}=2\times\frac{Precision\times{Recall}}{Precision+Recall}$
As most of NER systems involve multiple entity types, it is often required to assess the performance across all entity classes. Two measures are commonly used for this purpose:
Macro-averaged F-score
Computes the F-score independently for each entity type, then takes the average(hence treating all entity types equally).
Micro-averaged F-score
Aggregates the contributions of entities from all classes to compute the average(treating all entities equally).
绝大多数的NER任务需要识别多种实体类别,需要对所有的实体类别评估NER的效果。基于这个思路,有两类评估指标:
- 宏平均 F-score(macro-averaged F-score):分别对每种实体类别分别计算对应类别的 F-score,再求整体的平均值(将所有的实体类别都视为平等的)
- 微平均 F-score(micro-averaged F-score):对整体数据求 F-score(将每个实体个体视为平等的)
Relaxed-match Evaluation
MUC-6 defines a relaxed-match evaluation: a correct type is credited if an entity is assigned its correct type regardless its boundaries as long as there is an overlap with ground truth boundaries; a correct boundary is credited regardless an entity’s type assignment. Thus, complex evaluation methods are not widely used in recent NER studies.
MUC-6 定义了一种宽松匹配评估标准:只要实体的边界与实体真正所在的位置有重合(overlap)且实体类别识别无误,就可以认定实体类别识别正确;对实体边界的识别也不用考虑实体类别识别的正确与否。与精确匹配评估相比,宽松匹配评估的应用较少。
Traditional Approaches to NER
Rule-based Approaches
Rule-based NER systems rely on hand-crafted rules. Rules can be designed based on domain-specific gaztteers, and syntactic-lexical patterns.
These systems are mainly based on hand-crafted semantic and syntactic rules to recognize entities. Rule-based systems work very well when lexicon is exhaustive. Due to domain-specific rules and incomplete dictionaries, high precision and low recall are often observed from such systems, and the systems can not be transferred to other domains.
基于规则的NER系统依赖于人工制定的规则。规则的设计一般基于句法、语法、词汇的模式以及特定领域的知识等。当字典大小有限时,基于规则的NER系统可以达到很好的效果。由于特定领域的规则以及不完全的字典,这种NER系统的特点是高精确率与低召回率,并且类似的系统难以迁移应用到别的领域中去:基于领域的规则往往不通用,对新的领域而言,需要重新制定规则且不同领域字典不同。
Unsupervised Learning Approaches
A typical approach of unsupervised learning is clustering. Clustering-based NER systems extract named entities from the clustered groups based on context similarity. The key idea is that lexical resources, lexical patterns, and statistics computed on a large corpus can be used to infer mentions of named entities.
典型的无监督方法如聚类可以利用语义相似性,从聚集的组中抽取命名实体。其核心思路在于利用基于巨大语料得到的词汇资源、词汇模型、统计数据来推断命名实体的类别。
Feature-based Supervised Learning Approaches
Applying supervised learning, NER is cast to a multi-class classification or sequence labeling task. Given annotated data samples, features are carefully designed to represent each training example. Machine learning algorithms are then utilized to learn a model to recognize similar patterns from unseen data.
利用监督学习,NER任务可以被转化为多分类任务或者序列标注任务。根据标注好的数据,研究者应用领域知识与工程技巧设计复杂的特征来表征每个训练样本,然后应用机器学习算法,训练模型使其对数据的模式进行学习。
Deep learning Techniques for NER
Why Deep Learning for NER?
There are three core strengths of applying deep learning techniques to NER:
- NER benefits from the non-linear transformation, which generates non-linear mappings from input to output. Compared with linear models(e.g., loglinear HMM and linear chain CRF), deep-learning models are able to learn complex and intricate features from data via non-linear activation functions.
- Deep learning saves significant effort on designing NER features. The traditional feature-based approaches require considerable amount of engineering skill and domain expertise. Deep learning models are effective in automatically learning useful representations and underlying factors from raw data.
- Deep neural NER models can be trained in an end-to-end paradigm, by gradient descent. This property enables us to design possibly complex NER systems
三个主要的优势:
- NER可以利用深度学习非线性的特点,从输入到输出建立非线性的映射。相比于线性模型(如线性链式CRF、log-linear隐马尔可夫模型),深度学习模型可以利用巨量数据通过非线性激活函数学习得到更加复杂精致的特征。
- 深度学习不需要过于复杂的特征工程。传统的基于特征的方法需要大量的工程技巧与领域知识;而深度学习方法可以从输入中自动发掘信息以及学习信息的表示,而且通常这种自动学习并不意味着更差的结果。
- 深度NER模型是端到端的;端到端模型的一个好处在于可以避免流水线(pipeline)类模型中模块之间的误差传播;另一点是端到端的模型可以承载更加复杂的内部设计,最终产出更好的结果。
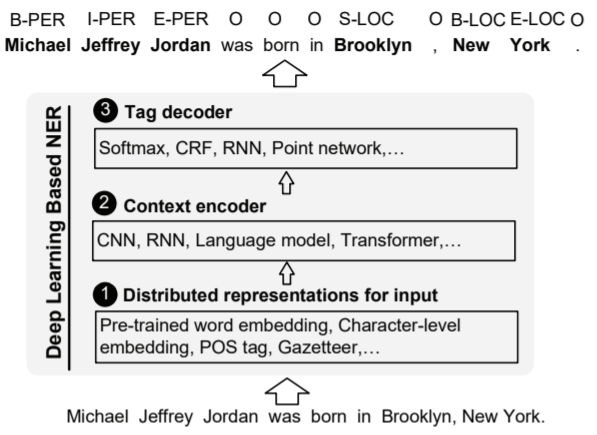
Taxonomy
The taxonomy of DL-based NER. FRO input sequence to predicted tags, a DL-based NER model consists of:
- Distributed representations for input
- Context encoder
- Tag decoder
文章针对现有的深度NER模型提出了一种新的归纳方法。这种归纳法将深度NER系统概括性的分为了三个阶段:
- 输入的分布式表示(distributed representation)
- 语境语义编码(context encoder)
- 标签解码(tag decoder)
一个深度NER系统的结构示例如下:
Distributed Representations for Input
A straight forward option of representing a word is one-hot vector representation. In one-hot vector space, two distinct words have completely different representations and are orthogonal. Distributed representation represents words in low dimensional real-valued dense vectors where each dimension represents a latent feature. Automatically learned from text, distributed representation captures semantic and syntactic properties of word, which do not explicitly present in the input to NER.
Three types of distributed representations that have been used in NER models:
- Word-level Representation
- CBOW, continuous bag-of-words
- continuous skip-gram model
- Character-level Representation
- Hybrid Representation
分布式语义表示:一个单词的含义是由这个单词常出现的语境(上下文)所决定的
一种直接粗暴的单词表示方法为 one-hot 向量表示。这种方法通常向量的维度太大,极度稀疏,且任何两个向量都是正交的,无法用于计算单词相似度。分布式表示使用低维度稠密实值向量表示单词,其中每个维度表示一个隐特征(此类特征由模型自动学习得到,而非人为明确指定,研究者往往不知道这些维度到底代表的是什么具体的特征)。这些分布式表示可以自动地从输入文本中学习得到重要的信息。深度NER模型主要用到了三类分布式表示:
- 单词级别表示
- 字符级别表示
- 混合表示
Word-level Representation
Usually, each word can be represented by a low-dimensional real value vector after training. Using as the input, the pre-trained word embeddings can be either fixed or further fine-tuned during NER model training.
通常经过训练,每个单词可以用一个低维度的实值向量表示。
作为后续阶段的输入,这些词嵌入向量既可以在预训练之后就固定,也可以根据具体应用场景进行调整。
Commonly used word embeddings include:
Examples:
- Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme use Word2Vec for end-to-end joint extraction model learning to obtain word representations as model input
- Fast and accurate entity recognition with iterated dilated convolutions The lookup table in their model are initialized by 100-dimensional embeddings trained on SENNA corpus by skip-n-gram.
Character-level Representation
Character-level representation has been found useful for exploiting explicit sub-word-level information such as prefix and suffix. Another advantage of character-level representation is that it naturally handles out-of-vocabulary. Thus character-based model is able to infer representations for unseen words and share information of morpheme-level regularities.
字符级别的表示能更有效地利用次词级别信息如前缀、后缀等。其另一个好处在于它可以很好地处理 out-of-vocabulary 问题。字符级别的表示可以对没有见过的(训练语料中未曾出现的)单词进行合理推断并给出相应的表示,并在语素层面上共享、处理信息(语素:最小的的音义结合体)。主流的抽取字符级别表示的结构分为:
There are two widely-used architectures for extracting character-level representation:
- CNN-based
- RNN-based
Figures below illustrate the two architectures:
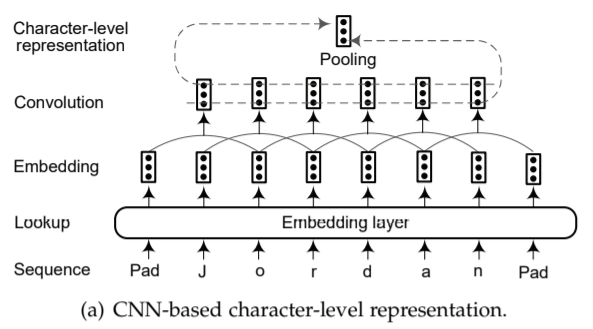
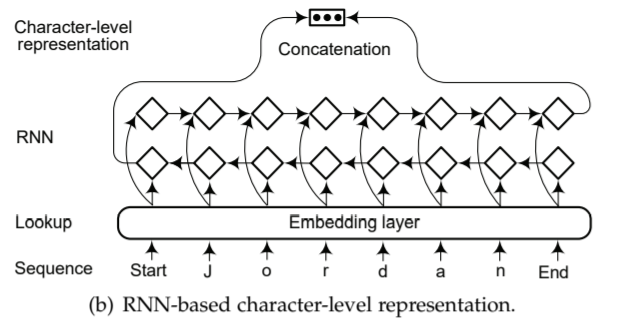
Examples:
- CNN-based: Deep contextualized word representations(ELMo)
- RNN-based: CharNER
Hybrid Representation
Some studies also incorporate additional information(e.g., gazetteers and lexical similarity) into the final representations of words, before feeding into context encoding layers. In other words, the DL-based representation is combined with feature-based approach in a hybrid manner. Adding additional information may lead to improvements in NER performance, with the price of hurting generality of these systems.
某些单词表示研究还结合了一些其他信息,例如句法信息、词法信息、领域信息等。这些研究将这些附加的信息与单词表示或字符级别的表示相结合作为最终的单词表示,之后再作为输入输入到后续的语义编码结构当中。换而言之,这种方法的本质是将基于深度学习的单词表示与基于特征的方法相结合。这些额外的信息可能可以提升NER系统的性能,但是代价是可能会降低系统的通用性与可迁移性。
Examples:
Context Encoder
The second stage of DL-based NER is to learn context encoder from the input representations.
The widely-used context encoder architectures are:
- Convolutional Neural Networks, CNN
- Recurrent Neural Networks, RNN
- Recursive Neural Networks
- Neural Language Models
- Deep Transformer
Convolutional Neural Networks
Collobert et al. proposed a sentence approach network where a word is tagged with the consideration of whole sentence:
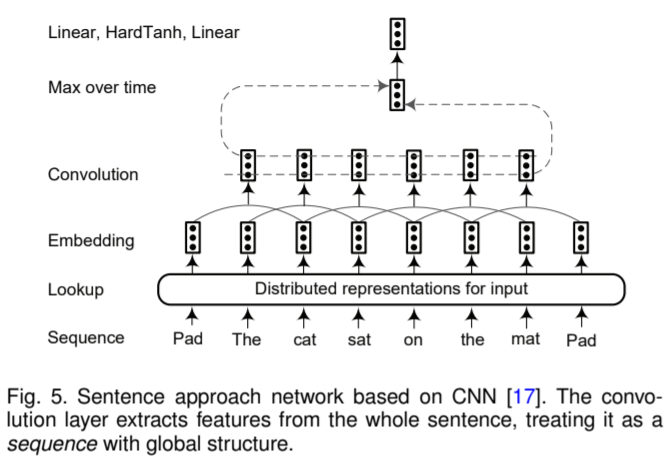
Each word in the input sequence is embedded to an N-dimensional vector after the stage of input representation. Then a convolutional layer is used to produce local features around each word, and the size of the output of the convolutional layers depends on the number of words in the sentence. The global feature vector is constructed by combining local feature vectors extracted by the convolutional layers. The dimension of the global feature vector is fixed, independent of the sentence length, in order to apply subsequent standard affine layers. Two approaches are widely used to extract global features: a max or an averaging operation over the position(i.e., “time” step) in the sentence. Finally, these fixed-size global features are fed into tag decoder to compute distribution scores for all possible tags for the words in the network input.
输入表示阶段,输入序列中的每一个词都被嵌入一个 N 维的向量。在这之后,系统利用卷积神经网络来产生词间的局部特征,并且此时卷积神经网络的输出大小还与输入句子的大小有关。随后,通过对该局部特征施加极大池化(max pooling)或者平均池化(average pooling)操作,我们能得到大小固定且与输入相互独立的全局特征向量。这些长度大小固定的全局特征向量之后将会被导入标签解码结构中,分别对所有可能的标签计算相应的置信分数,完成对标签的预测。
Recurrent Neural Networks
Recurrent neural networks have demonstrated remarkable achievements in modeling sequential data, together with its variants such as:
- Gated Recurrent Unit, GRU
- Long-short Term Memory, LSTM
In particular, bidirectional RNNs efficiently make use of past information(via forward states) and future information(via backward states) for a specific time frame. Thus, a token encoded by a bidirectional RNN will contain evidence from the whole input sentence. Bidirectional RNNs therefore become de facto standard for composing deep context-dependent representations of text.
循环神经网络在处理序列输入时效果优秀,它有两个最常见的变种:
- GRU(gated recurrent unit)
- LSTM(long-short term memory)
特别的,双向循环神经网络(bidirectional RNNs)能同时有效地利用过去的信息和未来的信息,即可以有效利用全局信息。因此,双向循环神经网络逐渐成为解决 NER 这类序列标注任务的标准解法。
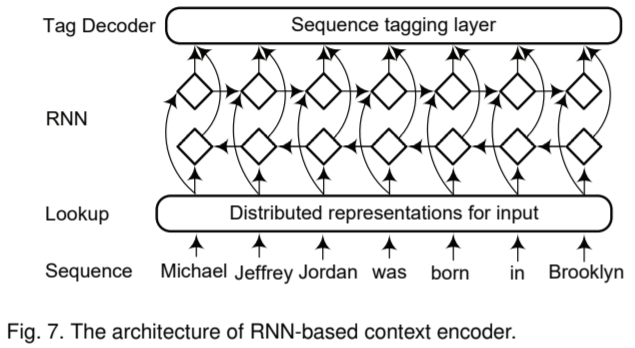
Example:
- Bidirectional lstm-crf models for sequence tagging is among the first to utilize a bidirectional LSTM CRF architecture to sequence tagging tasks (POS, chunking and NER).
Recursive Neural Networks
Recursive neural networks are non-linear adaptive models that are able to learn deep structured information, by traversing a given structure in topological order. Named entities are highly related to linguistic constituents, e.g., noun phrases. Typical sequential labeling approaches take little into consideration about phrase structures of sentences, however, recursive neural network can effectively use the structural information to obtain better prediction results.
递归神经网络是一种非线性自适应的模型,它可以学习得到输入的深度结构化信息。命名实体与某些语言成分联系十分紧密,如名词词组。传统的序列标注方法几乎忽略了句子的结构信息(成分间的结构),而递归神经网络能有效的利用这样的结构信息,从而得出更好的预测结果。
Example:
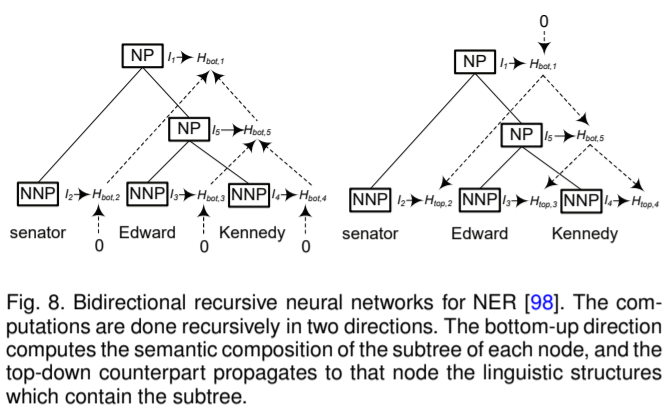
Neural Language Model
Language model is a family of models describing the generation of sequences. Given a token sequence, $(t_1,t_2,…,t_N)$, a forward language model computes the probability of sequence by modeling the probability of token $t_k$ given its history $t1,…,t_{k−1}$: $p(t_1,t_2,…,t_N)=\prod\limits_{k=1}^Np(t_k|t_1,t_2,…,t_{k-1})$ A backward language model is similar to a forward language model, except it runs over the sequence in reverse order, predicting the previous token given its future context: $p(t_1,t_2,…,t_N)=\prod\limits_p(t_k|t_{k+1},t_{k+2},…,t_N)$ For neural language models, probability of token tktk can be computed by the output of recurrent neural networks. At each position $k$, we can obtain two context-dependent representations (forward and backward) and then combine them as the final language model embedding for token $t_K$. Such language-model-augmented knowledge has been empirically verified to be helpful in numerous sequence labeling tasks.
Example:
- Semi-supervised sequence tagging with bidirectional language models 文章认为,利用单词级别表示作为输入来产生上下文表示的循环神经网络往往是在相对较小的标注数据集上训练的。而神经语言模型可以在大型的无标注数据集上训练。文中模型同时使用词嵌入模型与神经语言模型对无监督的语料进行训练,得到两种单词表示;之后模型中省去了将输入向量转化为上下文相关向量的操作,直接结合前面得到的两类单词表示并用于有监督的序列标注任务,简化了模型的结构。
Deep Transfomer
Examples:
- Attention is all you need
- Bert: Pretraining of deep bidirectional transformers for language understanding
Tag Decoder
Tag decoder is the final stage in a NER model. It takes context-dependent representations as input and produce a sequence of tags corresponding to input sequence.
The paper summarizes four architectures of tag decoder:
标签解码是NER模型中的最后一个阶段。在得到了单词的向量表示并将它们转化为上下文相关的表示之后,标签解码模块以它们作为输入并对整个模型的输入预测相应的标签序列。主流的标签解码结构分为四类:
- Multi-Layer Perceptron(MLP) + Softmax
- Conditional Random Fields, CRFs
- Recurrent Neural Networks
- Pointer Networks
Multi-Layer Perceptron + Softmax
With a multi-layer Perceptron + Softmax layer as the tag decoder layer, the sequence labeling task is cast as a multi-class classification problem. Tag for each word is independently predicted based on the context-dependent representations without taking into account its neighbors.
利用这个结构可以将NER这类序列标注模型视为多类型分类问题。基于该阶段输入的上下文语义表示,每个单词的标签被独立地预测,与其邻居无关。
Example:
- Fast and accurate entity recognition with iterated dilated convolutions
- Leveraging linguistic structures for named entity recognition with bidirectional recursive neural networks
Conditional Random Fields
A conditional random field(CRF) is a random field globally conditioned on the observation sequence. CRFs have been widely used in feature-based supervised learning approaches. Many deep learning based NER models use a CRF layer as the tag decoder.
条件随机场(conditional random fields)是一类概率图模型,在基于特征的有监督方法中应用广泛,近来的许多深度学习方法也使用条件随机场作为最后的标签标注结构。
CRFs, however, cannot make full use of segment-level information because the inner properties of segments cannot be fully encoded with word-level representations.
然而,CRFs不能充分利用段级信息,因为段的内部属性不能完全用字级表示进行编码。
Example:
Recurrent Neural Networks
A few studies have explored RNN to decode tags.
Deep active learning for named entity recognition reported that RNN tag decoders outperform CRF and are faster to train when the number of entity types is large
一些研究使用 RNN 来预测标签。
Deep active learning for named entity recognition这篇文章中提到,RNN 模型作为预测标签的解码器性能优于 CRF,并且当实体类型很多的时候训练速度更快
Point Networks
Pointer networks apply RNNs to learn the conditional probability of an output sequence with elements that are discrete tokens corresponding to the positions in an input sequence. It represents variable length dictionaries by using a softmax probability distribution as a “pointer”.
- Pointer Networks first applied pointer networks to produce sequence tag
- Neural Models for Sequence Chunking first identify a chunk (or a segment), and then label it. This operation is repeated until all the words in input sequence are processed
指针网络应用RNNs来学习输出序列的条件概率,其中输出序列中的元素是与输入序列中的位置相对应的离散标记。它使用softmax概率分布作为一个“指针”来表示可变长度字典
- Pointer Networks 首次提出此种结构
- Neural Models for Sequence Chunking 第一篇将pointer networks结构应用到生成序列标签任务中的文章